The Quest Begins
Today is December 29th in Vancouver, and I just arrived here 14 days ago (December 14, 2023). I've always wanted to watch movies that I find interesting in theaters. In downtown Vancouver, there is only one theater that shows Indian films, which is the Rio Theatre.
The problem is that the Rio Theatre only shows a selected number of films from India; they do not release all the movies. So, if I want to know if there will be movies that I like released in this theater, I need to check the history of movies that have been released there.
This is the journey of discovering which Indian movies have been released at the Rio Theatre.
The Motivation
But you may ask, what are you going to do with this information? It will allow me to sleep peacefully tonight. Right now, it's 12:46 AM on Saturday, December 30, 2023, and I'm just obsessed with this. I also want to know if the movie "Viduthalai" was released here because I am very excited about the second part of the "Viduthalai" movie. You could say that's another reason for wanting to know this information.
The First Step: Gathering Movie Information
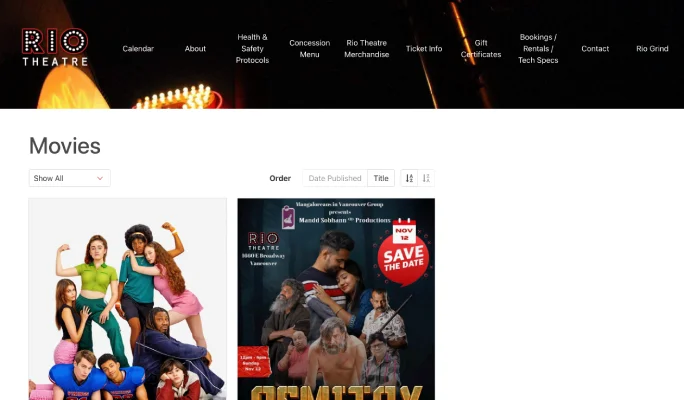
The page at https://riotheatre.ca/movie/page/6/?orderby=post_date lists all the movies released at the Rio Theatre, but there's a problem: I cannot view all the movies at once. To find all Indian movies, I must go through each page, click on the next button to go to a new page, and repeat the same step again and again.
To automate this process, I initially searched for any API that the frontend is calling so I could directly access all the information. Unfortunately, there was no API call because the site is server-rendered. It was just plain HTML that is sent to the browser. So, if I want to get all the movies, I need to somehow scrape through all the pages and extract the information to save it to a database.
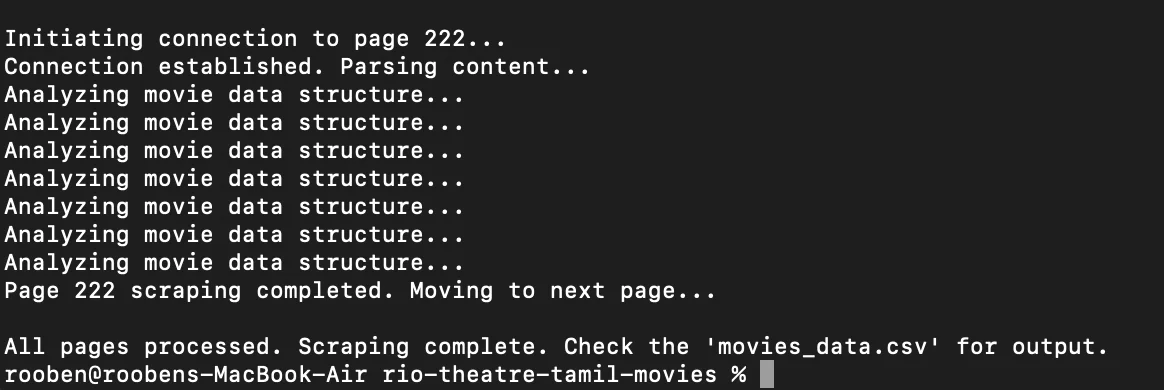
For your information: a single page is limited to showing only 10 movies, and there are a total of 222 pages, so there are approximately around 2220 movies.
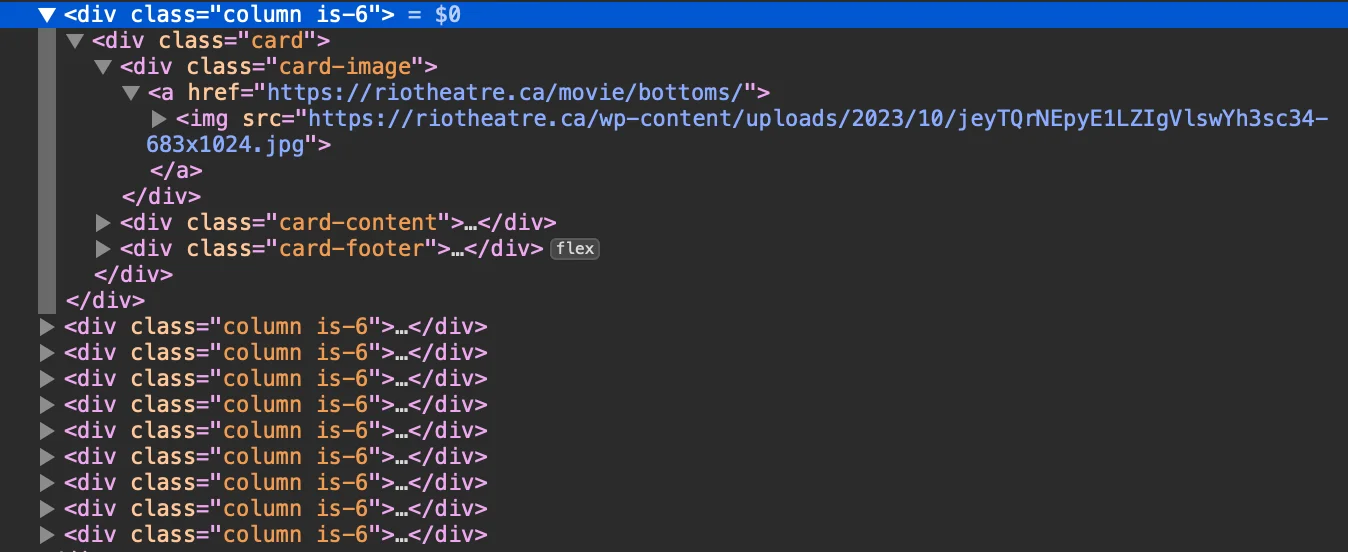
The HTML structure is the same for all pages, so I just have to loop through all the pages somehow and extract the information in the div with the class "column."
The Approach
I am a UX engineer, and I am more into UI and stuff, but I also do adventures like this once in a while. I knew i want to use BeautifulSoup, which is a parsing library to extract information from HTML. So, I used my good old friend GPT to create the Python code.
SPOILER : It didn't work right out of the box
Code Execution
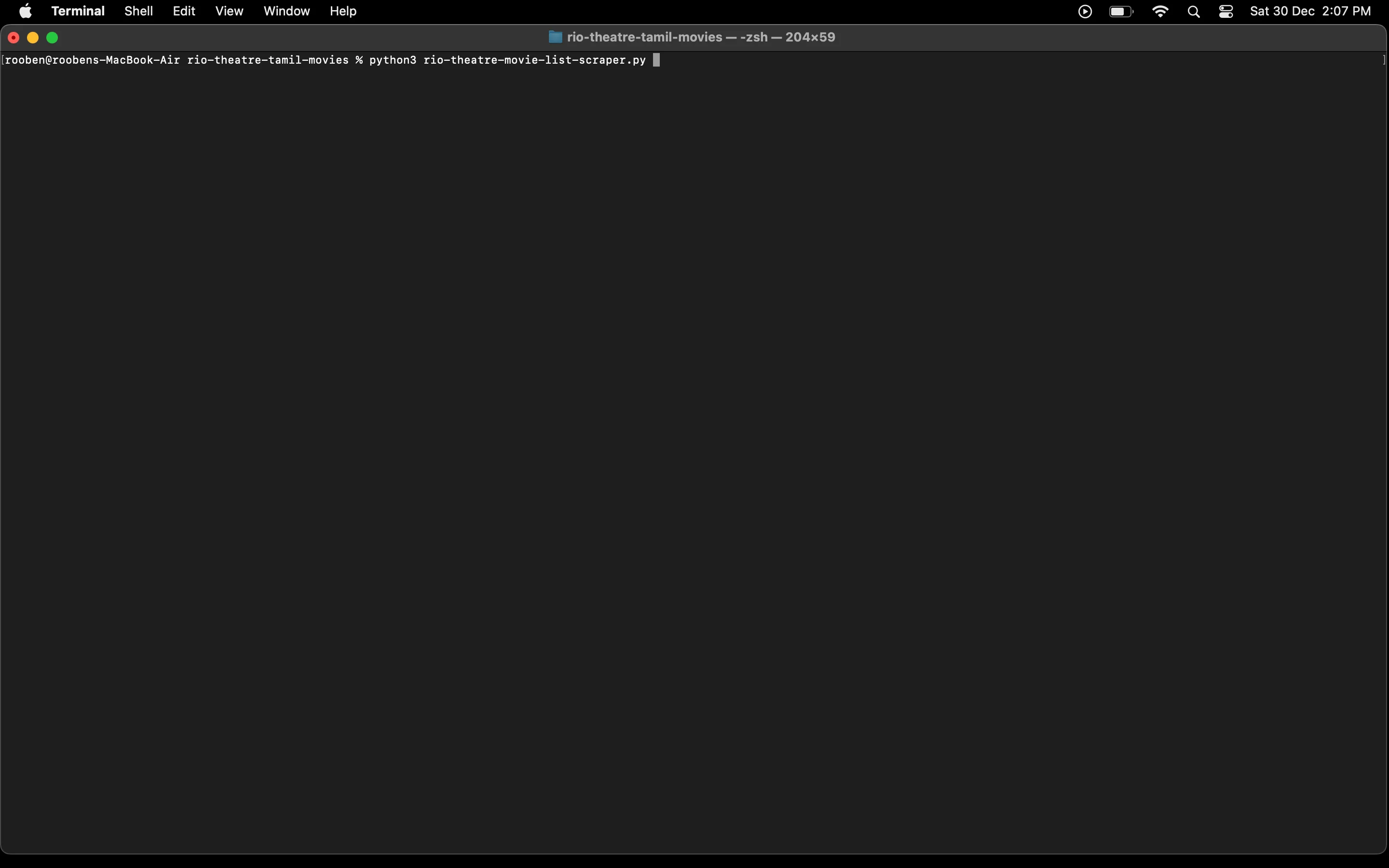
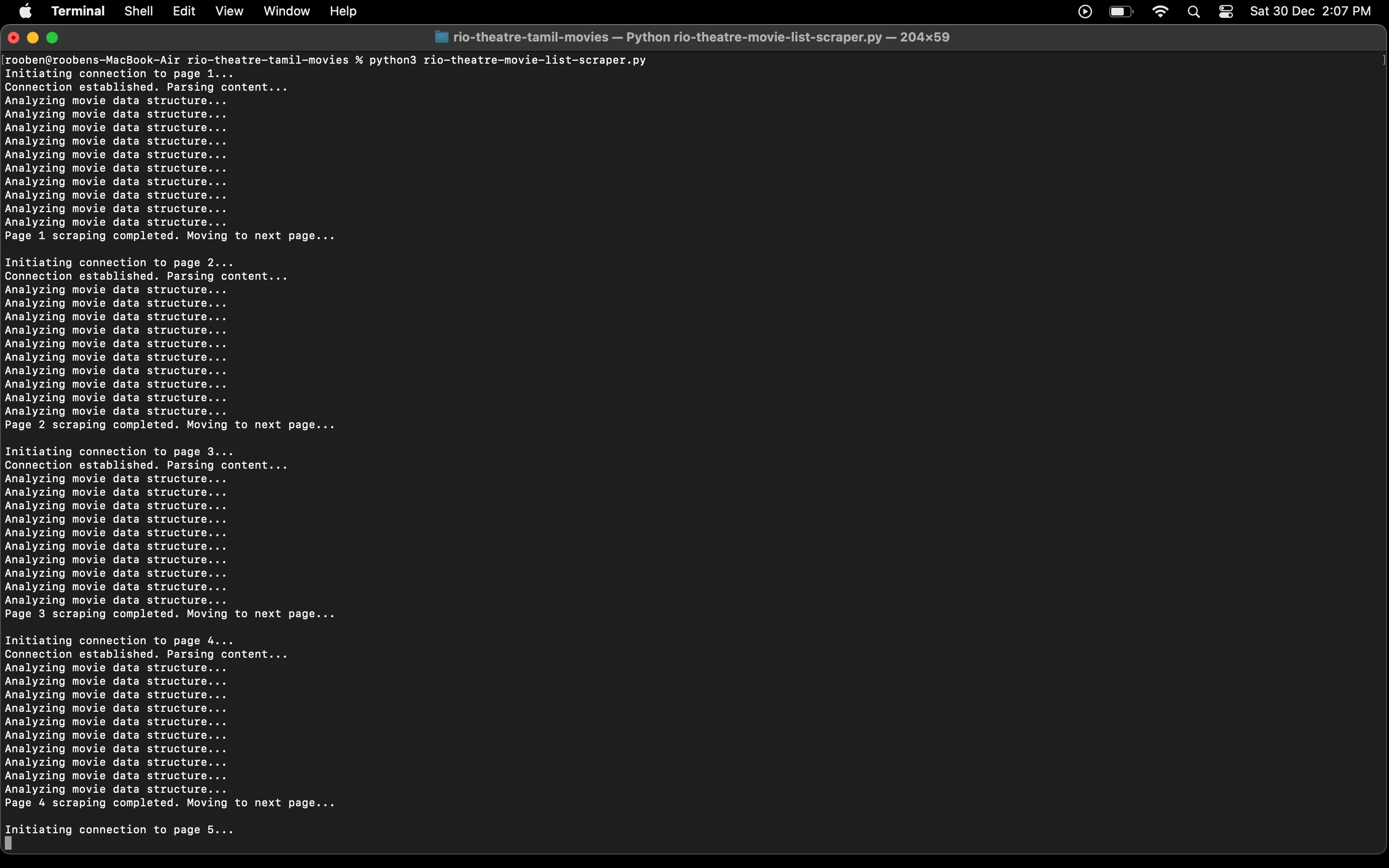
The code ran successfully.
The file was created, but it contained no data.
Resolving Issues
After a lot of troubleshooting, here’s what I found:
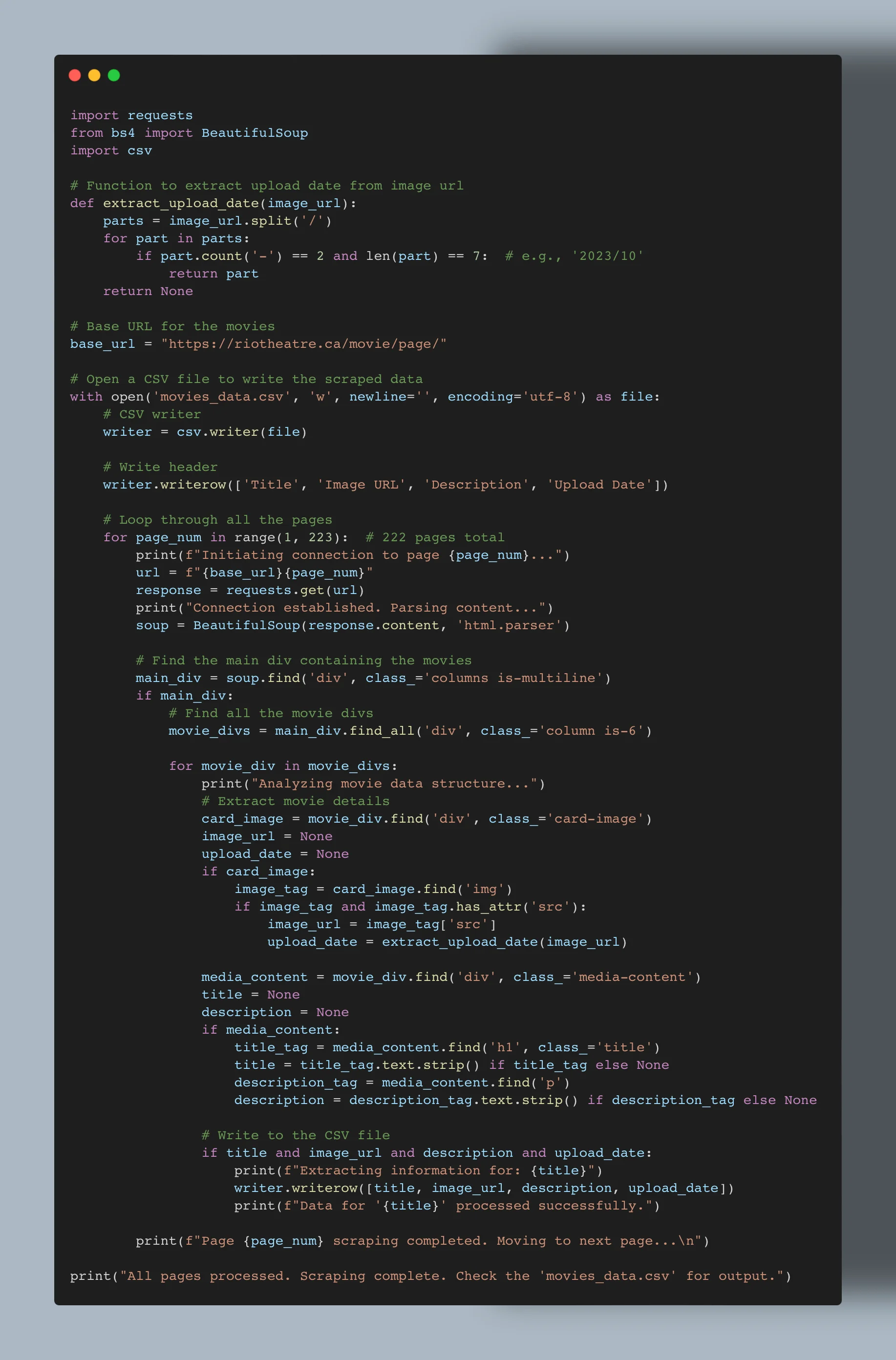
- Line 33 was the main reason no data was extracted. I removed this line and directly searched through the class name "column is-6."

- A silly mistake - The code to extract the upload date function was not working because it had an AND condition at the end to check if there was no upload date, don't save it. It was a silly mistake, but hey, GPT gets it wrong sometimes. So I just changed the AND operator to OR to fix this.

Success at Last
With the issues fixed, I reran the code for just one page to not have to wait too long:
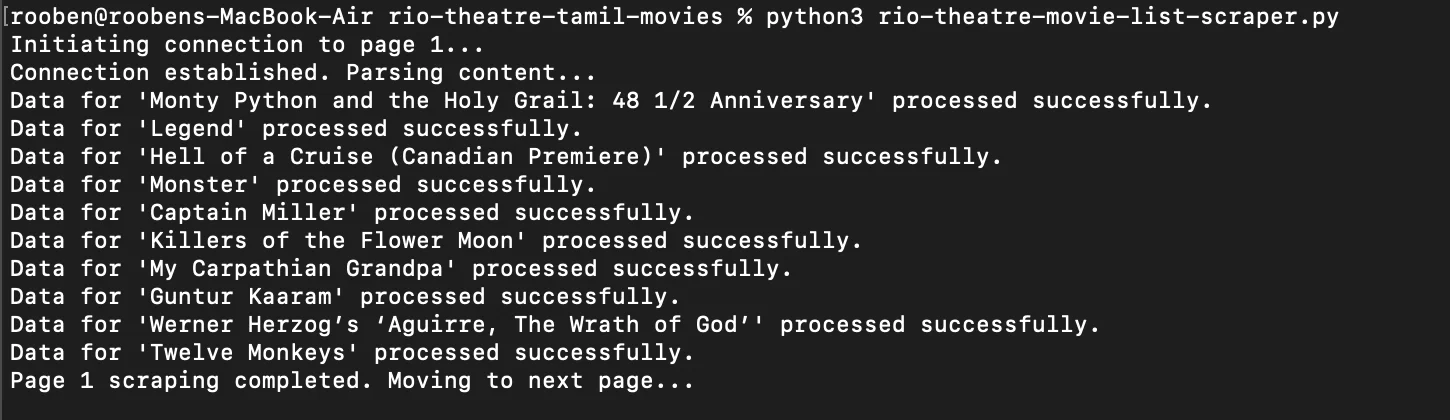
And finally, the results were as expected:

The time is now 1:34 AM, and it finally works. Now I want to run it for all 222 pages.

CSV file containing all the movies released in rio theatre.

The Final Code